Building an Arbitrage Bot

I've been fascinated by MEV (Maximal Extractable Value) for a while now, and over the past few weeks, I’ve started building my own arbitrage bot. It’s been a challenging yet insightful journey, and I’d like to share my experience so far.
What is MEV?
People trade funds, people watch them trading funds, people found ways to make profits based on funds being traded. To be honest, this is not today's topic, and it's a very vast field. To learn more, this article may help you.
Starting with the Basics
To begin this adventure, I decided to explore the implementation of a CowSwap solver.
For those unfamiliar, CowSwap is an off-chain order book where solvers compete to submit the most efficient on-chain settlement. Since all solvers use the same underlying liquidity sources, the competition lies less in speed or on-chain monitoring tricks, and more in algorithmic quality (from what I understand).
I figured this would be a great way to get hands-on experience with arbitrage using real-world tools, while also learning from the CowSwap ecosystem itself.
Unfortunately, that turned out to be a bit optimistic. The competitiveness of an arbitrage system is deeply tied to its performance — which means that sharing strategies often undermines profitability. So, I quickly realized that there wouldn’t be much help available when it came to solving the core problems.
That said, I followed CowSwap’s documentation closely and was able to get the full local stack up and running, including syncing with the live order book.
I chose to implement my solver in C++ — for once, it wasn’t overkill. I was surprised to find I was already familiar with many of the liquidity models: Uniswap V2/V3, Balancer’s stable and weighted pools, and a few others. The remaining pool types seemed negligible.
Then the Real Challenge Hit
The complexity came when I had to actually write the algorithm — and I had no clear direction. Neither the documentation nor any online resource offered much guidance.
An ideal solver algorithm would likely involve:
- Graph theory, to identify optimal trade paths
- Game theory, to balance solver profitability with order competitiveness
- Mathematical modeling, to simulate off-chain liquidity movements
- Handling limit orders, partial orders, and other edge cases
In short, this problem is likely NP-complete, requiring advanced algorithms and a deep mathematical foundation. I had just thrown myself headfirst into the deep end of arbitrage complexity.
Can You Still Get Results Without a PhD Team?
That’s the question I began asking myself. Is it possible to simplify the problem and/or reduce the level of competition? It was clear that I had no chance to compete with the big players, even after a few months of development.
One idea came to mind: target a newer blockchain — one that’s less mature in terms of ecosystem and developer tooling. That would mean less competition, and maybe a better learning ground.
Enter HyperEVM
My search led me to HyperEVM, a relatively new EVM-compatible blockchain developed by Hyperliquid. It felt like stepping into the Wild West.
Why HyperEVM was promising:
- Low gas fees
- Modest but exploitable trading volume
- EVM compatibility (making integration much easier)
- Fewer active arbitrage bots, due to its early-stage ecosystem
So I began roughing out a system that could serve as an arbitrage bot on this new chain. I’ll describe the different directions I explored to improve the bot’s profitability. I experimented as much as I could and tried to learn by doing, testing every idea that seemed viable.
The Adventure Begins
Choosing an EVM-compatible chain seemed like a great idea — in theory, it would allow me to port this system to any other EVM-compatible chain later on. In practice, though, things turned out to be more complicated due to protocols specificities.
The First Proof of Concept
To build my proof of concept (PoC), I needed a few key components:
- Fast access to on-chain data
- Off-chain liquidity simulation for Uniswap-like pools
- The ability to send on-chain transactions with protection against slippage
I started with a QuickNode RPC, but quickly hit the 200 requests/sec limit. That capped me at monitoring roughly 30 pools during testing.
I integrated Hyperswap and Kittenswap, the two most active DEXs on HyperEVM.
My first approach, somewhat naive, was to look for arbitrage loops that start and end with the same token. That way, there's no need to rely on price approximations (e.g., A → B → A or A → B → C → A). I deployed a smart contract capable of executing multiple swaps and reverting if the final balance was lower than the initial one. This ensure that the bot will never spend more than it earns.
function execute(
Trade[] calldata trades,
uint256 amountIn,
address startToken
) external payable returns (uint256) {
uint256 balanceBefore = IERC20(startToken).balanceOf(address(this));
// ... perform trades ...
uint256 balanceAfter = IERC20(startToken).balanceOf(address(this));
// This line will revert all the previous operations and stop the execution
require(balanceAfter > balanceBefore, "Arbitrage failed");
return balanceAfter - balanceBefore;
}
In TypeScript, I implemented functions to compute expected token outputs for Uniswap V2 and approximated Uniswap V3 swaps — V3 is more complex due to its tick system while V2 is pretty straightforward.
To detect arbitrage opportunities, I wrote a simple brute force algorithm that computes the best arbitrage path for a given input amount.
I decided to hardcode the input amount to 1 HYPE, and to ignore the gas cost of the transaction because it was extremely low at the time.
The First Result
With everything wired up, I ran the bot, stepped away for 20 minutes… and came back to see my first profitable transaction — about $0.30 at the time.
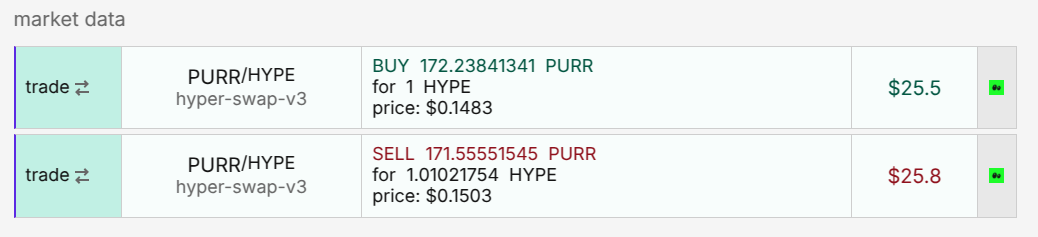
My first arbitrage transaction on HyperEVM. Source Purrsec.
It was a small gain, but a huge morale boost. At that point, I believed I was close to a viable system. With a dedicated node and estimated infrastructure costs around $100/month, profitability seemed achievable.
Spoiler: I still had a long road ahead. Competition would ramp up quickly in the days to come. But in hindsight, that initial optimism was crucial — if I had only focused on the months of work and potential financial losses ahead, I might have stopped right there.
Moving Toward Production
So far, here's a diagram of my architecture — each module is explained below.
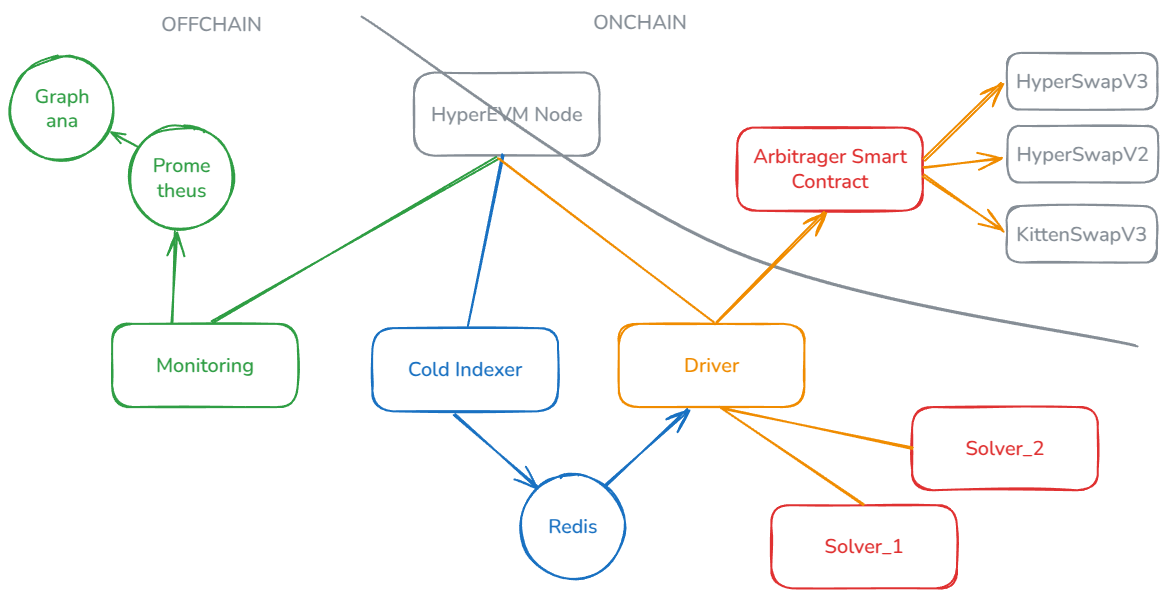
Colors are just here to make things prettier 👌.
HyperEVM Custom Node
My first step toward production was setting up a local node. This gave me full on-chain access with low latency and no rate limits. I didn't follow the advice from the documentation, which recommended using a node in Japan to reduce latency issues, even though it was cheaper in the US. I eventually switched and ended up losing several days syncing the node with a machine in Tokyo due to latency issues.
Cold data Indexer
I needed a way to cache persistent data (e.g., token names, decimals, pool tokens). So I wrote an indexer that stores data in Redis, refreshed periodically.
Solvers
Each solver receives a request from the driver and solves a graph to find arbitrage paths. Initially, this logic was in JavaScript for rapid prototyping. Later, I migrated to C++, which was 80x faster on average — crucial when tracking many pools. It is the same brute force algorithm I used in the PoC.
inline void find_best_arbitrage_cycle(
const std::vector<std::vector<const Api::LiquidityPoolTradePath *>> &all_cycles,
const Api::uint256 amount_in,
Api::uint256 &best_amount_out,
std::vector<const Api::LiquidityPoolTradePath *> &best_cycle
) {
for (const auto &cycle : all_cycles) {
try {
const Api::uint256 amount_out = compute_cycle_amount_out(cycle, amount_in);
if (amount_out > best_amount_out) {
best_amount_out = amount_out;
best_cycle = cycle;
}
} catch (Math::InvalidLiquidityStateError &e) {
continue;
} catch (const std::exception &e) {
std::cout << "Error: " << e.what() << std::endl;
}
}
}
Note that I was heavily inspired by CowSwap. It was important for me to design the system with multiple solvers from the start, as this would allow for horizontal scaling of the solving process, as well as safe comparison of different algorithms — since each solution is evaluated and put in competition with the others.
Monitoring
To monitor performance, I built a metrics indexer that feeds Prometheus, which powers Grafana dashboards.
To be honest, I under-invested here. I'm still missing key insights and can’t precisely track profit/loss over time. The idea was to compare strategies and versions of the arbitrage engine, but I’ve mostly been busy building essential features.
You can see in the following screenshot that this allows me to visualize the increase in the contract's balances (due to arbitrage activity) and the amount of HYPE available to cover transaction fees for the wallets responsible for calling the arbitrageur.
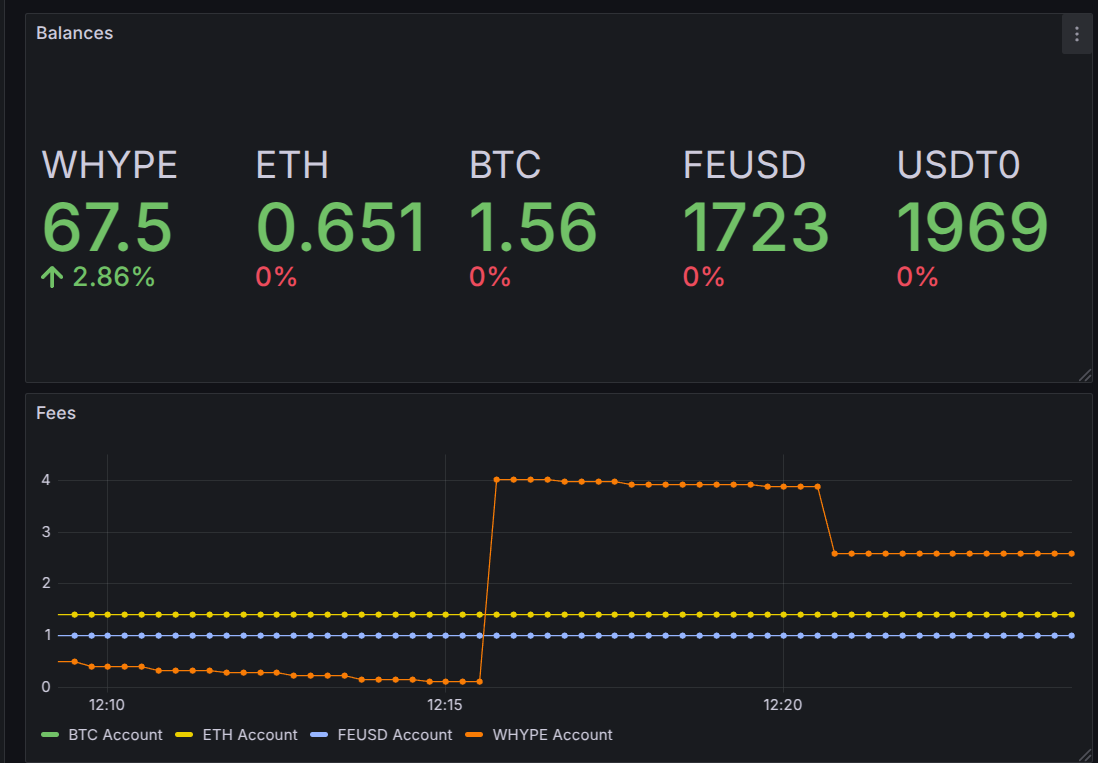
Grafana dashboard (with a bug regarding BTC decimals).
Driver
I built a central coordination module called the Driver (also inspired by CowSwap’s architecture). It’s responsible for:
- High-frequency data collection
- Structuring the data into a standard request format
- Sending requests to all available solvers
- Collecting and evaluating responses within a strict timeout
- Comparing the results to determine the best solver and submit the transaction
Simulating gas cost and submitting transactions reliably was another challenge. I eventually introduced a dynamic fee deduction, setting aside a portion of profit to cover validator fees and ensure transaction inclusion. I am still not convinced with this approach, but I have no better idea for now.
Thanks to the strategy of using multiple solvers, I was able to narrow down the list of cryptocurrencies used to initiate arbitrage cycles. This increases the number of opportunities, as it allows for shorter arbitrage loops.
For example, a cycle like A → B → C → B → A can be shortened to B → C → B, saving two transactions if the contract already holds B.
Responses are evaluated and filtered — in the PoC, I hardcoded the input token amount to 1 HYPE, which was suboptimal. Profits vary significantly depending on input size.
To omptimize the input size estimation, I tried different strategies:
Offchain computation
Off-chain calculation is fast and reliable — if you have accurate models and complete data. For Uniswap V2, the math is simple. For V3, it’s evil.
In the PoC, I used a rough approximation to avoid tick-level math. To compute real outputs with Uniswap V3's SDK, you need all tick data, which is extremely resource-intensive — even with a private node.
My idea was to fetch a subset of ticks because arbitrage transactions are often low-volume. I managed to code the math but the delays were still significant when it came to fetch the data. I finally gave up this approach for the next strategy.
Onchain computation
Instead of fully computing everything off-chain, I opted for a hybrid approach:
- Approximate swaps using a constant-tick assumption (ie. Uniswap V3 math approximation)
- Collect all promising trade paths
- Simulate each candidate on-chain via a custom smart contract (a read-only call)
- Use binary search (dichotomy) to find the input amount that maximizes profit
This approach is based on the fact that the data is available, but communication between the driver and the node results in significant latency. Even when both programs run on the same machine, each request still has to go through the full network stack. Since tick retrieval can't be properly parallelized, fetch times become a bottleneck.
Instead, the node is tasked with simulating a smart contract execution. This way, it uses the same math as the actual contracts (eliminating the risk of errors) and has direct, optimized access to its own data.
This gave me much better results while avoiding heavy off-chain computation. Here is a snippet of the binary search function, it returns the optimal k value (ie. the best amount) to maximize the profit:
function binarySearchOptimalK(
Trade[] calldata trades,
uint256 step,
uint256 balance
) internal returns (uint256) {
uint256 low_k = 1;
uint256 high_k = balance / step;
while (low_k < high_k) {
uint256 mid_k = low_k + (high_k - low_k) / 2;
uint256 profitMid = computeTradesProfit(
trades,
mid_k * step
);
uint256 profitNext = computeTradesProfit(
trades,
(mid_k + 1) * step
);
if (profitMid >= profitNext) {
high_k = mid_k;
} else {
low_k = mid_k + 1;
}
}
return low_k;
}
And this is costless because I am simulating this call (even though it's a write function).
Smart Contract Module
My first smart contract was simple, and it worked well initially. The main purpose is to prevent the bot to concretely loose funds (e.g. Spend 1 A and obtain 0.98 A).
But as my whole bot system matured, it became clear that the contract was critical to profitability.
Profit calculation is straightforward: profit = total_output - total_input - gas_cost.
But when a transaction fails, you still pay the gas — often due to a competing bot front-running your trade. These failed transactions became increasingly costly due to the gas price increasing of a ~500x factor (HyperEVM became more popular).
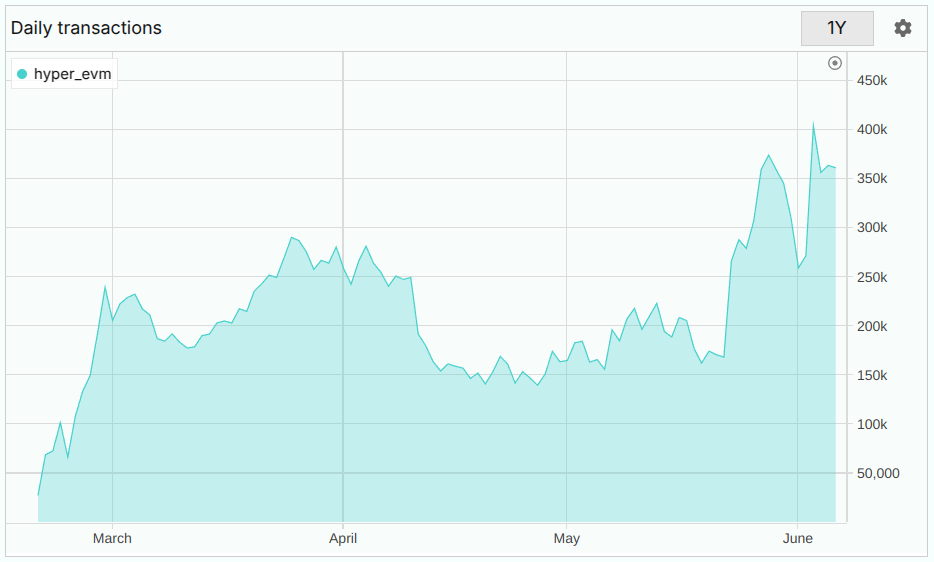
HyperEVM daily transactions. Source Purrsec.
To mitigate this:
- I optimized gas usage with basic Solidity gas optimizations
- Introduced an early-exit condition before the final balance comparison (
balanceAfter < balanceBefore) - Tweaked execution to minimize unnecessary operations
This lowered the average cost per trade significantly, but not enough.
Current Results & Next Steps
As of now, the bot is not yet profitable. On average, I recover only ~80% of the input.
To bridge the gap to profitability, I have two main ideas:
- Reduce fees further
- Use heuristics to detect and avoid unprofitable trades
The second option seems most promising — I haven’t explored it yet, and it requires a larger dataset to analyze trade outcomes at scale. I'll need to analyze all trades performed and hopefully find patterns that reduce the number of failed transactions.
Also, I face a new challenge: latency.
Block time on HyperEVM has dropped to under 1 second (2 seconds originally). Because my experiments run from a machine in US, network latency to the HyperEvm sequencers (hosted in Tokyo) is hurting my competitiveness.
I’ll need a new setup — ideally a server located closer to the sequencer region — to reduce latency and stay in sync.
Final Thoughts
There’s still a long road ahead, but I believe it’s worth it. I’ve learned a ton about arbitrage, on-chain mechanics, and smart contract optimization — and I’m only getting started.